 什么是RAG
什么是RAG
# 什么是 RAG?
RAG 的全称是 Retrieval-Augmented Generation,中文意思是检索增强生成。它是目前解决大语言模型(LLM)知识有限、容易“胡说八道”这一核心问题最主流、最有效的方法之一。
核心思想:让 AI 先“查资料”再“回答问题”
你可以这样理解 RAG 的本质:
RAG = 搜索引擎 + 智能整理器 + 语言模型
大模型的困境:
时效性,传统的 LLM(如ChatGPT刚诞生的时候)像一个“知识面很广但记忆力有限的学生”——他什么都学过一点,但细节记不清,而且学的东西有截止日期。如果训练数据的截止日期是 2023 年 4 月,你问他“2023 年 6 月的天气”,他完全不知道,因为他的知识停留在训练时的那一刻,要么它就开始编。
“幻觉”,它能用非常专业的语气,给你讲一个完全不存在的事实,而你很难一眼看出来。
“数据局限性”,它对你的内部数据一无所知。你公司的制度、产品文档、项目记录,这些从没出现在它的训练集里,它当然不可能知道。
RAG 的思路:从闭卷到开卷
面对这三个问题,最直接的解决方式就是——让模型不再闭卷考试,而是给它开卷的机会。
RAG(检索增强生成)做的就是这件事。它分为三步:
- 先从外部知识库里把跟问题相关的材料找出来;
- 把这些材料连同问题一起打包;
- 让模型基于这些材料来回答问题。
RAG 的做法是:在回答问题之前,先让 AI 去外部知识库(比如公司内部文档、网页、数据库)实时检索相关信息,然后基于检索到的信息来组织回答。
这样一来,AI 的回答就有了事实依据,而不是凭空编造。
这样一来,回答就有了事实依据,知识库可以随时更新,私有数据也能安全接入,幻觉问题也会大幅减少。
# ✅ RAG 解决了什么核心问题?
| 传统 LLM 的痛点 | RAG 如何解决 |
|---|---|
| 知识过时 | 实时从外部知识库检索最新信息,不受训练时间限制 |
| 产生幻觉(编造事实) | 要求模型基于检索到的文档回答,答案有据可查 |
| 无法处理私有数据 | 可以将公司内部文档、数据库作为外部知识源 |
| 缺乏透明度 | 可以返回引用的文档来源,用户可核实 |
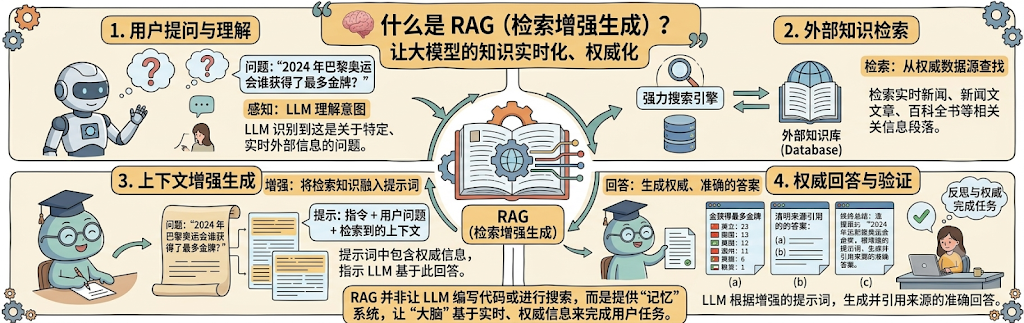
# RAG 的完整工作流程是什么
RAG (检索增强生成) 的完整工作流程如图所示:
- 第一步:用户提问与理解
- 用户提出一个涉及特定或实时信息的具体问题。
- 例如:“2024 年巴黎奥运会谁获得了最多金牌?”
- LLM 感知此问题并识别到这并非其基础知识可直接回答,需要寻求外部数据的帮助来完成任务。
- 第二步:外部知识检索
- LLM 识别到意图后,触发 RAG 系统开始行动。
- RAG 作为一个连接器,通过“强力搜索引擎”向“外部知识库 (Database)”发起检索。
- 外部知识库中包含了实时新闻、新闻文章、百科全书等相关信息,系统从中检索并找到最相关的相关段落。
- 第三步:上下文增强生成
- RAG 将检索到的外部知识融合进提示词中,这一步被称为“增强”。
- 新的提示词包含:
- LLM 的基础指令(例如:参考以下信息,给出权威回答)
- 用户的问题
- 检索到的具体、相关的上下文信息(例如:含有金牌榜数据的相关新闻段落)
- 提示词中包含了权威、准确的信息,指示 LLM 基于此回答。
- 第四步:权威回答与验证
- LLM 接收增强的提示词作为输入。
- 通过对提示词中包含的检索信息的分析和处理。
- LLM 生成准确、权威的答案,并引用检索到的来源(例如:引用具体的新闻来源和数据)。
- 最终生成并引用来源的准确回答。
RAG 并非让 LLM 编写代码或进行搜索,而是提供“记忆”系统,让“大脑”基于实时、权威信息来完成用户任务。这实现了 RAG 的核心目标:让大模型的知识实时化、权威化。
# RAG 与 Finetune(微调)的区别
很多人会把 RAG 和微调搞混,它们的区别可以这样理解:
| 对比维度 | RAG(检索增强生成) | Finetune(微调) |
|---|---|---|
| 方式 | 动态检索外部知识,不修改模型本身 | 用新数据重新训练/微调模型参数 |
| 知识更新 | 实时,知识库更新即可生效 | 需要重新训练,周期长、成本高 |
| 成本 | 较低,仅需向量存储和检索 | 较高,需要 GPU 算力和训练数据 |
| 适用场景 | 知识密集、需要实时更新的场景(如客服、企业知识库) | 需要模型改变行为方式的场景(如模仿特定写作风格) |